

Accurate velocity models are essential but the ‘start-stop-start-stop’ process to create them is time-consuming and laborious in geologically complex areas, where workflows require significant manual intervention. An automated and repetitive Monte Carlo approach to model building optimizes turnaround while maintaining or improving quality.
- Automates velocity model building to achieve an accelerated project turnaround
- Uses a highly-optimized and cost-effective tomographic inversion to create a velocity model
- Uses a large population of random models as part of a Monte Carlo optimization problem, where statistical weight constrains and assists model accuracy
- Significantly reduces turnaround even when using a small cluster, but massive parallelization enables greater acceleration
- Can be used directly for depth migration, or to support Full Waveform Inversion (FWI)
Challenges with Quick Turnaround in Velocity Model Building
Traditional depth imaging velocity model building (VMB) is usually a top-down approach, run in a start-stop fashion. It typically includes the following: first, determine the constraints for the inversion and then run the inversion, before checking the results, conditioning the results, and applying the model. This continues in a rinse-and-repeat manner, working down the data until the VMB is complete. In general, model 1 becomes model 2, which becomes model 3, and so on. In practice, models 2a and 2b may have been work that was attempted and discarded before arriving at model 3. It is a highly non-linear and fitful approach, prone to errors because of the single in-out model approach, and heavily dependent on manual intervention. Consequently, VMB can be a slow process, especially in more challenging geological environments.
A Different Approach – Big Data Automation
Monte Carlo simulations use random sampling to solve problems where the solution is not sufficiently defined. When performing an inversion for velocity model building we use observations drawn from the data to infer the values of the true earth model. However, most inversion-based velocity model-building methods are under-determined, meaning the solution is non-unique because the observations are insufficient to constrain the inversion to the singular, correct answer. Monte Carlo simulations of the model space accommodate some of these limitations.
The schematic below describes how hyperModel works. The number of models used in the Monte Carlo simulation (Perturbation i) and the number of loops the process uses (n Loops) depends upon the data - both the starting model accuracy (Initial Model M1) and the seismic data quality (Input data). The simplified workflow creates a velocity model in a global sense by minimizing manual intervention, as the protracted ‘start-stop’ of classical model building is replaced by a compute-intensive one determined using optimized and parallelized resources. Limiting manual intervention enables the user to focus on the convergence of the model to a desired result, which is achieved in a much-reduced timeframe by shifting the operation to a compute-demanding procedure.
A map outlining the survey area for the hyperModel project in the Campos Basin.
Future developments for hyperModel will include incorporating supervised machine learning approaches to high-grade the observations used to constrain the inversion. A well-taught system should limit noise and multiple-contamination of observations, enabling less pre-conditioning of the input data, and further reducing turnaround.
hyperModel Case Study – a Teaser from Brazil
PGS acquired the first two parts of the deepwater Campos Basin data in 2020, using multisensor streamer acquisition, and covering an area of greater than 7 000 sq. km. The over-burden postsalt data is complex, characterized by local basins and a prominent fault regime. There are highly mobile salt bodies overlain with fast and laterally inconsistent carbonate layers. The presalt section is laterally heterogeneous and is heavily faulted.
A map outlining the survey area for the hyperModel project in the Campos Basin.
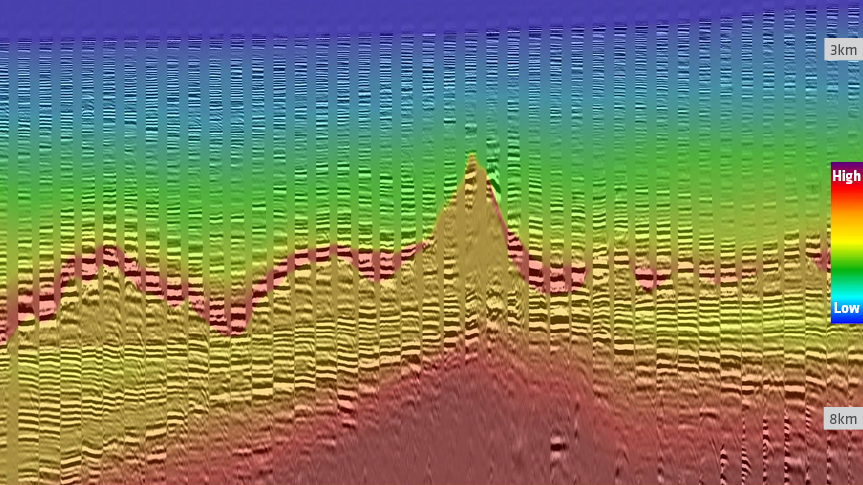
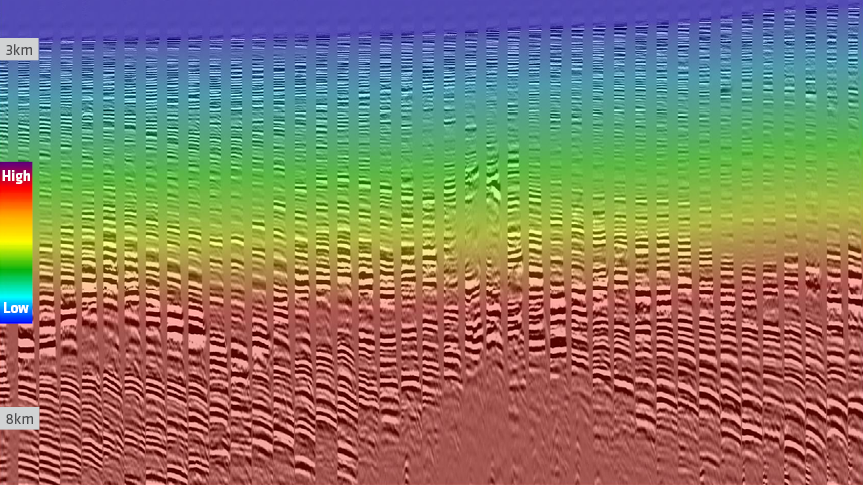
The PGS hyperModel simulation ran in two parts, initially solving the postsalt section. An automatic horizon tracing algorithm based on waveform genotype segmentation helped pick most of the fast carbonate and top-salt mask. Following a salt flood, the same network determined the base salt, and the Monte Carlo simulation then solved the presalt section. The first image below displays the benign input model and migrated Common Image Gathers (CIGs) from the part one region, and shows areas of significant under- and over-corrected moveout on the CIGs. The output from the model building is shown in the second image. CIGs are flatter and the model is geologically consistent, especially in the presalt section. The model building took less than four weeks, with the hyperModel component taking approximately two weeks.
"By using PGS hyperModel, we have reduced the turnaround time for the super-fast-track, generating a suitable model for depth imaging of an accelerated product, enabling PGS to deliver data to a client in fall 2020, well in advance of Brazil's 17th bidding round in 2021," says PGS Senior Reservoir Geophysicist, Yermek Balabekov.
- Find out more about Campos Basin super-fast track delivery with hyperModel
A Fertile Future Ground - Concluding Remarks
Reducing turnaround is a key objective of PGS and also a goal of the industry. One way to achieve this is to move from manually intensive processes to those that offload the effort to massively parallelized computing. Monte Carlo simulations enable this for velocity model building, while additionally solving some of the challenges of conventional methods with statistics. PGS hyperModel has been shown to work on a variety of datasets, reducing turnaround for model building by more than an order of magnitude.
Contact a PGS expert
If you have a question related to our Imaging & Characterization services or would like to request a quotation, please get in touch.